FastAPI + Celery 기반 증명사진 자동 보정 서버. 5단계 톤 보정, 4종 AI 모델, 비동기 태스크 큐.
2025.06 ~ 현재|1인 설계 / 구현 / 운영
PythonFastAPICeleryPyTorchOpenCVMediaPipe
1 / 4
개요
이미지 보정 서버
증명사진 자동 보정 서버. 키오스크 촬영 원본을 받아 얼굴 크롭, 톤 보정, 배경 제거, 얼굴 복원을 수행하고 결과를 반환한다. FastAPI + Celery 기반, Python.
개발 형태: 1인 설계 / 구현 / 운영
기간: 2025.06~ (진행 중)
배경
키오스크 촬영 사진의 보정이 사람 손에 의존하고 있었다. 조명 환경, 카메라 설정, 프린터 특성이 현장마다 다르고, 소프트웨어 단의 이미지 보정이 전무한 상태. 현장 직원이 카메라 드라이버 값을 수동 조정하는 방식이라 촬영 품질이 기기마다 달랐고, 일관된 출력을 보장할 수 없었다.
조명이 어둡든 밝든, 색온도가 치우쳐 있든 관계없이 동일한 출력 품질을 만들어내는 서버가 필요했다.
해결
파이프라인 단계별 처리 결과
FastAPI + Celery 기반 이미지 보정 서버를 설계하고 구현했다. 키오스크가 촬영 원본을 HTTP로 전송하면, 서버에서 얼굴 감지부터 최종 복원까지 전체 파이프라인을 자동 실행하고 결과를 반환한다.
5단계 자동 톤 보정. 이미지의 밝기 분포와 채널 비율, 컬러 불균형 지수를 수치 분석한 뒤, 얼굴 기반 밝기 조정, 히스토그램 레벨, 색온도 보정, LAB 컬러 밸런스, 딥러닝 화이트밸런스를 순서대로 적용한다. 각 단계의 파라미터가 이미지 특성에 따라 자동 조절되며, 이전 단계의 결과를 기반으로 다음 단계가 동작하는 구조.
4종 AI 모델 통합. MediaPipe로 얼굴을 감지하고 크롭하며, Deep WB U-Net으로 화이트밸런스를 보정하고, InSPyReNet으로 배경을 제거하며, GFPGAN으로 얼굴을 복원한다. 모델마다 입출력 형식, 해상도 제약, GPU/CPU 요구가 모두 다르지만 단일 파이프라인에서 순차 실행된다. 어느 단계에서 실패해도 원본을 유지하는 구조.
비동기 처리 아키텍처. Celery + Redis 태스크 큐로 ML 추론을 비동기 처리한다. 리버스 프록시가 복수의 클라이언트 환경을 분리하고, 환경별로 파이프라인 옵션을 달리 적용한다. Supabase 업로드는 fire-and-forget으로 처리하여 응답 지연에 영향을 주지 않는다.
기술 스택
영역
기술
적용
API / 비동기
FastAPI, Celery, Redis
6개 엔드포인트, 태스크 큐, 결과 브로커
이미지 처리
OpenCV, NumPy, PIL
존 분석, 히스토그램 레벨, 색온도, 컬러 밸런스
AI 모델
PyTorch, GFPGAN, InSPyReNet
얼굴 복원, 배경 제거, 화이트밸런스
얼굴 감지
MediaPipe
얼굴 탐지, 랜드마크 검출, 뺨 밝기 측정
스토리지
Supabase
이미지 저장, 디바이스 관리, API 로그
프록시
httpx, uvicorn
환경 분리, 요청 라우팅
문서 구성
문서
내용
01-자동-보정-파이프라인
5단계 AutoMastering, 존 분석, 얼굴 기반 밝기, 히스토그램 레벨, 적응적 화이트밸런스
02-딥러닝-모델-통합
Deep WB 파이프라인 통합, 피부 보호 마스크, GFPGAN 얼굴 복원, InSPyReNet 배경 제거
03-서비스-아키텍처
FastAPI + Celery 비동기 파이프라인, 프록시 환경 분리, 지연 초기화
2 / 4
자동 보정 파이프라인
이미지 분석 결과를 기반으로 밝기, 레벨, 색온도, 컬러 밸런스, 화이트밸런스를 순차 적용하는 5단계 톤 보정 시스템. 각 단계가 이미지 특성에 따라 파라미터를 자동 결정하고, 과보정을 방지하는 적응적 구조.
마스터링 보정 전후 비교
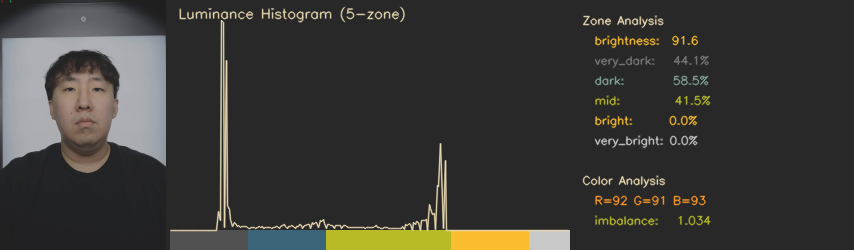
존 분석: 보정 판단의 근거
문제
이미지 보정을 자동화하려면, 먼저 "이 이미지가 어떤 상태인가"를 수치로 판단할 수 있어야 한다. 단순히 평균 밝기만으로는 "어두운 배경 + 밝은 얼굴" 같은 구도를 구별할 수 없고, 채널 평균만으로는 조명의 색온도 편향을 정량화할 수 없다. 보정 단계마다 필요한 정보가 다르고, 보정 전후의 변화를 추적할 수 있어야 과보정을 막을 수 있다.
접근
모든 보정에 앞서 analyze() 함수가 이미지의 밝기 분포와 색 특성을 수치화한다. 밝기를 5개 존으로 나누어 분포를 측정하고, R/G/B 채널 간 비율로 컬러 불균형 지수를 산출한다.
지표
산출 방식
용도
5존 밝기 분포
050, 50100, 100180, 180230, 230~255 각 비율
밝기 보정량 결정
채널 비율
rg_ratio, rb_ratio, gb_ratio
색온도 편향 판단
color_imbalance
max(비율들) / min(비율들)
AWB 적용 여부 결정
is_very_dark / is_dark
밝기 < 80 + very_dark_ratio > 0.6 등
밝기 보정 방향 결정
needs_color_protection
밝기 < 120 or 불균형 > 1.3
톤 조정 시 색상 보호
보정 전에 한 번, 보정 후에 한 번 분석을 수행한다. 보정 전후의 분석 결과를 비교하면 각 단계가 이미지를 어떻게 변화시켰는지 정량적으로 추적할 수 있다.
결과
존 분석 시각화
모든 보정 단계가 이 분석 결과를 근거로 파라미터를 결정한다. 예를 들어 color_imbalance가 1.09 미만이면 화이트밸런스를 건너뛰고, very_dark_ratio가 높으면 밝기 보정량을 키운다. 감이 아니라 수치에 기반한 판단 구조.
얼굴 기반 밝기 보정
문제
전체 이미지의 평균 밝기로 보정량을 결정하면, 실제 중요한 영역인 얼굴과 무관한 결과가 나온다. 어두운 배경에 밝은 얼굴이 있는 이미지는 "어둡다"로 분류되어 과도하게 밝아지고, 밝은 배경에 어두운 얼굴이 있으면 반대로 더 어두워진다. 증명사진에서 중요한 것은 배경이 아니라 얼굴의 밝기다.
접근
얼굴 기반 밝기 측정 시각화
MediaPipe FaceMesh로 얼굴 랜드마크를 검출하고, 양쪽 뺨 영역의 밝기를 직접 측정한다.
뺨을 측정 기준으로 선택한 이유가 있다. 이마나 코는 조명의 직접적인 반사가 발생하기 쉽고, 턱 아래는 그림자가 진다. 뺨은 얼굴에서 비교적 넓고 평탄한 영역이라, 조명 반사와 그림자의 영향을 가장 적게 받으면서 피부 톤의 대표값을 얻을 수 있다.
측정된 얼굴 밝기에 따라 보정 방향과 강도를 결정한다.
얼굴 밝기
보정 방향
최대 보정량
> 200
어둡게
35
> 180
어둡게
25
< 160
밝게
35
< 180
밝게
25
난관
MediaPipe가 얼굴을 감지하지 못하는 경우가 있다. 극단적인 노출(과노출/저노출), 심한 모션 블러, 비정면 자세 등. 얼굴 감지 실패 시 전체 파이프라인이 중단되면 서비스에 쓸 수 없다.
해결
얼굴 감지 실패 시 존 분석 결과로 대체한다. 전역 밝기 분포(is_very_dark, is_dark, is_bright 등)를 기반으로 보정량을 결정하되, 얼굴 기반 측정보다 보수적으로 적용한다. 추가로, color_imbalance가 1.4를 초과하면 보정값을 80%로 제한하여 색 왜곡이 큰 이미지에서 과보정을 방지한다.
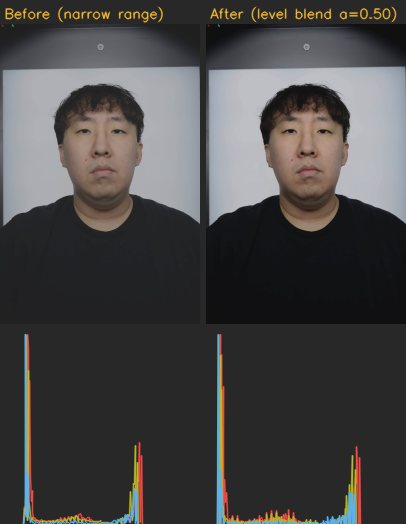
히스토그램 레벨 보정
문제
밝기 보정만으로는 콘트라스트 문제를 해결할 수 없다. 히스토그램이 좁은 범위에 몰려 있으면 밋밋하게 보이고, 넓게 분산되어 있으면 날카롭게 보인다. 단순히 히스토그램을 0~255로 스트레칭하면 어두운 이미지는 노이즈가 증폭되고 밝은 이미지는 하이라이트가 날아간다.
접근
히스토그램 레벨 보정 전후 비교
이미지의 "분위기"를 먼저 분석하고, 분위기에 맞는 레벨 범위를 적용한다.
_mood() 함수가 평균 밝기, 표준편차, 밝은/어두운 픽셀 비율로 이미지 특성을 분류한다.
분류
조건
min_percentile
max_percentile
어두운 이미지
mean < 80
0.02
0.98
밝은 이미지
mean > 170
0.03
0.97
저콘트라스트
std < 40
0.02
0.98
고콘트라스트
std > 80
0.08
0.92
기본
그 외
0.05
0.95
어두운 이미지에는 넓은 범위(298%)를 사용하여 어두운 영역의 디테일을 보존하고, 고콘트라스트 이미지에는 좁은 범위(892%)를 사용하여 극단값의 영향을 억제한다.
난관
레벨 보정을 전체 적용하면 이미 적정한 영역까지 변환되어 부자연스러워진다. 특히 밝은 픽셀이 많은 이미지(흰 배경, 밝은 조명)에서 과보정이 심했다.
해결
레벨 보정 결과를 원본과 블렌딩한다. 블렌딩 비율은 밝은 픽셀(>=230)의 비율에 따라 적응적으로 결정된다.
python
hi = float((gray >= 230).mean())
alpha = 0.35 if hi > 0.02 else 0.5
result = cv2.addWeighted(leveled, alpha, image, 1.0 - alpha, 0)
밝은 픽셀이 2%를 넘으면 블렌딩 비율을 0.35로 낮춰서 하이라이트 클리핑을 방지한다. 레벨 범위가 80 미만이면 보정 자체를 건너뛴다. 이미 충분히 분산된 히스토그램을 강제로 스트레칭할 이유가 없다.
적응적 화이트밸런스
문제
형광등, 백열등, LED 등 조명 종류에 따라 색온도가 다르고, 같은 조명이라도 설치 환경에 따라 편차가 크다. 화이트밸런스가 맞지 않은 사진은 노란빛이나 푸른빛이 돌아 증명사진으로서의 품질이 떨어진다.
그런데 화이트밸런스 보정은 양날의 검이다. 잘못 적용하면 피부톤이 회색이나 녹색으로 변하고, 원래 의도된 색감마저 파괴한다.
접근
화이트밸런스 보정 3열 비교
두 단계로 나누어 접근한다. 먼저 LAB 색공간에서의 전통적 보정으로 큰 편향을 잡고, 그 다음 Deep WB U-Net으로 미세 보정을 수행한다.
LAB + Gray World 컬러 밸런스. LAB 색공간에서 a, b 채널의 평균이 128(중립)에서 벗어난 정도를 L 채널(밝기)에 비례하여 보정한다. 밝은 영역은 강하게, 어두운 영역은 약하게 보정하여 그림자 영역의 색 왜곡을 방지한다. 이후 Gray World 가정(전체 이미지의 평균 색이 회색이어야 한다)에 기반한 채널별 스케일링을 적용한다. intensity를 0.2로 제한하여 과보정을 방지.
Deep WB(Afifi & Brown, CVPR 2020). 사전 학습된 U-Net 모델을 AWBProcessor 클래스로 래핑하여 파이프라인에 통합했다. 모델 자체는 그대로 사용하되, 조건부 실행 로직(color_imbalance >= 1.09일 때만 적용)과 피부 보호 마스크(HSV 기반 블렌딩)를 추가하여 프로덕션에서의 안정성을 확보했다. 상세 구현은 02-딥러닝-모델-통합 문서에서 다룬다.
난관
AWB가 필요 없는 이미지에 강제 적용하면 오히려 색이 틀어진다. 이미 화이트밸런스가 잡혀 있는 이미지를 다시 보정하면 중립 색이 편향되고, 의도적으로 따뜻한 톤을 준 이미지의 분위기가 파괴된다. 또한 AWB를 적용할 때 피부톤이 무채색 방향으로 끌려가는 현상이 있었다.
해결
두 가지 게이트를 적용한다.
적용 여부 게이트. 존 분석의 color_imbalance 값이 1.09 미만이면 화이트밸런스를 건너뛴다. 채널 간 비율 차이가 작다는 것은 이미 균형이 잡혀 있다는 의미이므로, 건드릴 이유가 없다.
결과 검증 게이트. AWB 결과가 유효한지 다중 조건으로 검증한다.
python
def _check_awb(result, shape):
if result is None or not isinstance(result, np.ndarray):
return False
if result.size == 0 or result.shape != shape:
return False
if np.isnan(result).any() or np.isinf(result).any():
return False
mean = float(np.mean(result))
return 1.0 <= mean <= 254.0
NaN, Inf, 극단적인 평균값(거의 검정 또는 거의 흰색)을 모두 거른다. 검증 실패 시 AWB를 적용하지 않고 이전 단계 결과를 유지한다.
피부 보호. HSV 색공간에서 피부색 범위를 마스킹하고, 피부 영역에서는 보정 강도를 60%로 제한한다. 피부가 아닌 영역은 AWB를 온전히 적용하되, 피부 영역은 원본 색감을 40% 유지하는 블렌딩 구조다. 상세 구현은 02-딥러닝-모델-통합 문서에서 다룬다.
환경별 파이프라인 분기
문제
모든 현장에 동일한 보정을 적용할 수 없다. 지점마다 조명 환경이 다르고, 클라이언트 환경에 따라 요구하는 처리 수준이 다르다.
해결
두 차원의 분기를 적용한다.
마스터링 모드 분기. 지점 코드에 따라 마스터링 모드가 결정된다.
조건
모드
파이프라인 차이
적색 조명 지점
Red
색온도 보정 단계 추가
보정 제외 지점
-
마스터링 전체 건너뜀
경량 클라이언트 환경
balanced
GFPGAN 비적용
기본
dramatic
전체 파이프라인
적색 조명이 강한 지점에서는 일반적인 보정으로 색온도 편향을 충분히 잡지 못한다. 이런 지점에 한해 색온도 추정 및 보정 단계(colorTemp.optimize)를 추가로 실행한다. 4가지 방법으로 색온도를 추정하고, 분산이 800K를 초과하면 4500~6500K로 클램핑하여 극단적인 보정을 방지한다.
처리 옵션 분기. 각 API 엔드포인트가 요청 파라미터와 환경에 따라 처리 옵션 dict를 구성한다. apply_crop, apply_gfpgan, apply_mastering, apply_rembg 각각을 독립적으로 제어할 수 있어, 동일한 파이프라인 코드로 6개 엔드포인트의 서로 다른 처리 조합을 모두 소화한다.
3 / 4
딥러닝 모델 통합
GFPGAN, InSPyReNet, Deep WB U-Net, MediaPipe 4종 모델을 단일 파이프라인에 통합. 모델별 해상도/입출력 제약을 흡수하고, 추론 실패 시 원본을 유지하는 방어적 구조.
화이트밸런스 모델 통합
문제
마스터링 파이프라인에서 LAB + Gray World 보정만으로는 복잡한 색온도 편향을 충분히 잡지 못하는 경우가 있었다. 형광등과 LED가 혼합된 환경이나, 벽면 반사가 색을 왜곡하는 환경에서는 전통적 알고리즘의 한계가 있다.
딥러닝 기반 화이트밸런스 모델 Deep WB(Afifi & Brown, CVPR 2020)를 파이프라인에 통합하기로 했다. 모델 자체는 사전 학습된 U-Net을 그대로 사용하되, 프로덕션 파이프라인에 맞는 래핑과 안전장치가 필요했다.
접근
AWBProcessor 클래스로 Deep WB 모델을 래핑하고, 세 가지 통합 로직을 추가했다.
조건부 실행: 모든 이미지에 AWB를 적용하면 이미 균형 잡힌 이미지의 색이 오히려 틀어진다. 존 분석의 color_imbalance 값이 1.09 미만이면 AWB를 건너뛴다.
피부 보호: AWB가 피부톤을 무채색 방향으로 끌어당기는 현상을 방지하기 위해 HSV 피부 마스크 블렌딩을 추가했다.
파이프라인 순서 배치: brightness, level, color balance 이후 마지막 단계에 배치. 앞선 보정으로 큰 편향이 잡힌 상태에서 미세 보정을 수행하는 구조.
난관
AWB를 적용했을 때 피부톤이 파괴되는 현상이 있었다. 따뜻한 조명 아래서 촬영된 사진의 피부는 원래 노란빛이 도는데, AWB가 이를 "색 편향"으로 판단하고 무채색 방향으로 끌어당긴다. 증명사진에서 피부가 잿빛으로 변하면 결과물의 품질이 오히려 하락한다.
또한 AWB 모델의 출력이 항상 유효하지는 않았다. 극단적인 입력(과노출, 단색에 가까운 이미지 등)에서 NaN이나 극단값이 나오는 경우가 있었다.
해결
조건부 실행 게이트. color_imbalance가 1.09 미만이면 AWB를 건너뛴다. 채널 간 비율 차이가 작다는 것은 이미 균형이 잡혀 있다는 의미이므로 건드릴 이유가 없다.
결과 검증 게이트. AWB 출력을 다중 조건으로 검증한다.
python
def _check_awb(result, shape):
if result is None or not isinstance(result, np.ndarray):
return False
if result.size == 0 or result.shape != shape:
return False
if np.isnan(result).any() or np.isinf(result).any():
return False
mean = float(np.mean(result))
return 1.0 <= mean <= 254.0
NaN, Inf, 극단적 평균값(거의 검정 또는 거의 흰색)을 모두 거른다. 검증 실패 시 AWB를 적용하지 않고 이전 단계 결과를 유지한다.
피부 보호 마스크. HSV 색공간에서 피부색 범위를 두 구간으로 정의한다.
범위
H
S
V
Range 1
0~20
20~255
70~255
Range 2
160~180
20~255
70~255
Range 1은 일반적인 피부색 범위, Range 2는 Hue가 래핑되는 구간의 붉은색 피부를 커버한다. 두 범위의 합집합으로 피부 마스크를 생성한다.
strength 0.6은 피부 영역에서 보정 적용 비율을 60%로 제한한다는 의미다. 피부가 아닌 영역(배경, 의류)은 AWB를 온전히 적용하되, 피부는 원본 색감을 40% 유지한다. 피부에 노란빛이 과도하게 남는 것도, 잿빛으로 빠지는 것도 방지하는 균형점이다.
얼굴 복원: GFPGAN
문제
GFPGAN 얼굴 복원 전후 비교
저해상도 카메라, 저조도 환경, 또는 크롭 후 리사이즈에서 얼굴의 디테일이 소실된다. 눈, 코, 입 주변의 텍스처가 뭉개지면 증명사진으로서의 품질이 떨어진다.
접근
GFPGAN(TencentARC) + facexlib + basicsr을 활용해 얼굴 복원 파이프라인을 구성했다. facexlib의 FaceRestoreHelper가 RetinaFace 기반 얼굴 탐지, 정렬, 512x512 크롭, 역 아핀 변환, 원본 붙여넣기를 처리한다. 이를 감싸는 FaceRestorer 래퍼와 GFPGANer 오케스트레이션 레이어에서 모델 초기화/경로 관리, 다중 얼굴 개별 복원, 실패 시 폴백, GPU 메모리 정리를 구현했다.
난관
enhance() 내부에서 탐지된 얼굴을 순회하며 개별적으로 GFPGAN 추론을 실행하는데, 개별 얼굴마다 복원이 실패할 수 있다. 하나의 얼굴 복원이 실패했다고 전체 이미지를 포기할 수는 없다. 또한 enhance()의 반환값은 (cropped_faces, restored_faces, restored_img) 튜플인데, 얼굴 미탐지 시 (None, None, img) 형태로 구조가 달라진다.
해결
개별 얼굴 복원 실패 시 해당 얼굴만 원본 크롭으로 대체하고 나머지는 정상 처리한다. paste_back=True로 역 아핀 변환을 수행해 복원된 얼굴을 원래 위치에 합성한다.
_parse_result()에서 반환값 튜플 구조의 변동을 방어적으로 파싱한다.
python
def _parse_result(self, result):
if result is None:
return None
if isinstance(result, tuple):
return result[2] if len(result) > 2 else result[0]
return result
모델 초기화는 get_gfpgan() -> init_gfpgan() 체인으로 처리한다. 모델 파일 경로 탐색, 아키텍처 타입 결정(GfpganConfigs), 더미 이미지 워밍업까지 포함한다. Windows 환경에서는 Triton 백엔드 미지원으로 torch.compile()을 비활성화하고, use_half=False로 fp32 추론을 사용한다.
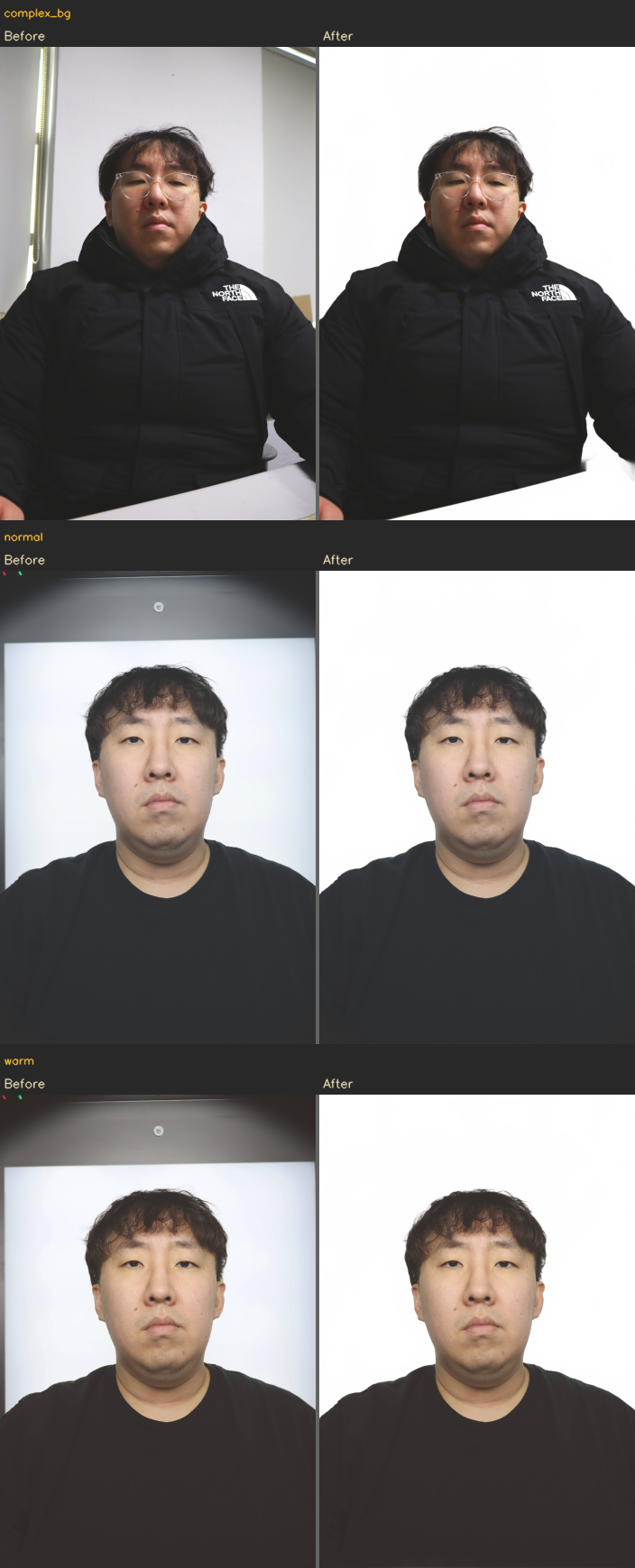
배경 제거: InSPyReNet
문제
배경 제거 결과
증명사진의 배경을 흰색으로 교체해야 한다. 배경이 복잡하거나 머리카락처럼 경계가 세밀한 영역에서 깔끔하게 분리하는 것이 관건이다.
해결
transparent_background 라이브러리(InSPyReNet 기반)를 BackgroundRemover 클래스로 래핑하여 파이프라인에 통합했다. 배경 분리 자체는 라이브러리가 처리하고, 래퍼에서 BGR/RGB 변환, numpy 배열 직접 전달(PIL 변환 오버헤드 제거), 에러 시 원본 반환을 담당한다.
파이프라인에서 마스터링 이후, 얼굴 복원 이전에 배치했다. 마스터링으로 톤이 정리된 상태에서 배경 제거를 수행해야 전경/배경 분리 정확도가 올라가고, 배경이 흰색으로 교체된 이미지에서 GFPGAN이 얼굴만 집중적으로 복원할 수 있다. 파이프라인 순서 자체가 각 모델의 입력 품질을 높이는 구조다.
얼굴 기반 크롭: MediaPipe
문제
크롭 프리셋 비교
증명사진은 규격이 정해져 있다. 420x540, 360x480, 600x600 등 5개 프리셋 크기에 맞춰 크롭해야 하며, 얼굴이 프레임 내 적절한 위치와 크기로 배치되어야 한다.
접근
MediaPipe FaceDetection으로 얼굴 위치를 감지하고, 프리셋별 오프셋과 배율로 크롭 영역을 계산한다.
python
@dataclass(frozen=True)
class CropPreset:
output_width: int
output_height: int
x_offset: float
w_multiplier: float
y_offset: float
h_multiplier: float
face_size 파라미터(0~20)로 얼굴 크기를 조절할 수 있다. 값이 커지면 크롭 영역이 좁아져 얼굴이 크게 나온다.
5개 프리셋을 dict[str, CropPreset]으로 관리하여, 새로운 규격이 추가되면 프리셋 하나만 등록하면 된다. _crop_face()에서 얼굴 바운딩 박스를 계산하고 프리셋 크기로 리사이즈한다. 얼굴이 감지되지 않으면 원본을 그대로 반환한다.
방어적 파이프라인 설계
4종 모델이 순차 실행되는 파이프라인에서, 하나의 모델 실패가 전체를 중단시키면 서비스로 쓸 수 없다.
모든 처리 모듈이 동일한 방어 패턴을 따른다.
python
def restore(self, image):
if self.gfpgan is None:
return image # 모델 없으면 원본
try:
result = self.gfpgan.enhance(image, ...)
restored = self._parse_result(result)
if restored is None:
return image # 파싱 실패면 원본
return restored
except Exception:
return image # 추론 실패면 원본
입력 검증, try/except, 결과 검증을 겹겹이 적용한다. BackgroundRemover, FaceRestorer, AutoMastering, AWBProcessor 모두 이 패턴을 공유한다. 크롭만 성공하고 나머지가 전부 실패해도, 크롭된 이미지는 정상적으로 반환된다.
ImageProcessor의 process() 메서드에서 각 단계를 PipelineTimer로 측정하므로, 어느 단계에서 시간이 오래 걸렸거나 건너뛰어졌는지 로그로 추적할 수 있다.
4 / 4
서비스 아키텍처
FastAPI + Celery + Redis 기반 비동기 이미지 처리 서비스. ML 모델 지연 초기화, 프록시 기반 멀티 환경 분리, fire-and-forget 업로드 패턴으로 응답 지연을 최소화하는 구조.
비동기 태스크 파이프라인
문제
이미지 보정 파이프라인은 크롭, 톤 보정, 배경 제거, 얼굴 복원을 순차 실행한다. 4종 AI 모델의 추론이 포함되어 처리 시간이 수십 초에 달한다. FastAPI의 요청 핸들러에서 이를 동기로 실행하면 워커 스레드가 점유되어 다른 요청을 받을 수 없고, 타임아웃 위험이 생긴다.
접근
Celery + Redis 조합으로 무거운 처리를 별도 워커 프로세스에 위임한다.
sequenceDiagram
participant C as Client
participant A as FastAPI
participant R as Redis
participant W as Celery Worker
C->>A: POST /modify/ (image)
A->>A: save_upload()
A->>R: queue_task.delay()
R->>W: dispatch
W->>W: ImageProcessor.process()
W-->>R: result
R-->>A: task.get(timeout=120)
A-->>C: FileResponse
API 서버는 파일 저장과 태스크 디스패치만 담당하고, 실제 처리는 Celery 워커에서 수행된다. task.get(timeout=120)으로 결과를 대기하되, asyncio.run_in_executor()로 래핑하여 FastAPI의 이벤트 루프를 차단하지 않는다.
난관
Celery 워커와 API 서버가 같은 코드베이스를 공유한다. service_worker.py를 import하면 ImageProcessor가 초기화되면서 4종 AI 모델이 메모리에 로드된다. API 서버는 태스크를 디스패치할 뿐 직접 처리하지 않으므로, 수 GB의 모델을 불필요하게 로드하는 셈이다.
해결
워커 프로세스에서만 ImageProcessor를 초기화하는 지연 로딩 구조를 적용했다.
python
_is_celery_worker = (
os.environ.get('CELERY_WORKER_RUNNING') == '1'
or 'celery' in sys.argv[0].lower()
)
image_processor = None
if _is_celery_worker:
image_processor = ImageProcessor()
환경변수 CELERY_WORKER_RUNNING 또는 sys.argv[0]의 'celery' 문자열로 워커 여부를 판별한다. API 서버 프로세스에서는 image_processor가 None으로 유지되어 모델 로드가 발생하지 않는다. queue_task 내부에서 None이면 그 시점에 초기화하는 이중 안전장치도 있다.
태스크 타임아웃
태스크
soft_time_limit
time_limit
queue_task
60초
120초
upload_task
30초
60초
soft limit에 도달하면 SoftTimeLimitExceeded 예외가 발생하여 graceful하게 중단할 수 있고, hard limit에 도달하면 워커가 태스크를 강제 종료한다.
프록시 기반 환경 분리
문제
동일한 이미지 서버를 복수의 클라이언트 환경에서 사용하지만, 환경마다 요구하는 처리 수준이 다르다. 어떤 환경에서는 GFPGAN 얼굴 복원까지 적용하고, 다른 환경에서는 톤 보정만 적용하는 식이다. 환경마다 서버를 따로 운영하면 리소스 낭비이고, 하나의 서버에서 요청마다 환경을 판별할 수 있어야 한다.
접근
리버스 프록시 레이어를 두어 환경 정보를 HTTP 헤더로 주입한다.
flowchart LR
C1["환경 A 클라이언트"]
C2["환경 B 클라이언트"]
P1["프록시 A\n:8080/:8082"]
P2["프록시 B\n:8081/:8083"]
IS["이미지 서버\n:7777"]
C1 --> P1
C2 --> P2
P1 -->|"X-Proxy-Environment=A"| IS
P2 -->|"X-Proxy-Environment=B"| IS
환경별로 별도의 FastAPI 프록시 앱이 고유 포트에서 리스닝한다. 모든 요청을 내부 이미지 서버(localhost:7777)로 전달하면서 X-Proxy-Port와 X-Proxy-Environment 헤더를 추가한다. 이미지 서버는 이 헤더를 읽어 환경을 판별한다.
해결
httpx.AsyncClient를 모듈 레벨 싱글톤으로 생성하여 커넥션 풀을 재사용한다. catch-all 라우트로 모든 경로와 메서드를 처리하고, host 헤더를 제거하여 upstream과의 충돌을 방지한다.
celery_app.control.inspect()로 워커 상태를 조회하고, 워커가 응답하지 않으면 status를 degraded로 변경한다. 전체 실패 시 unhealthy. 프록시 정보(X-Proxy-Port, X-Proxy-Environment)도 함께 반환하여, 어느 환경에서 어떤 포트로 접근했는지 추적할 수 있다.